Testing anti-patterns potpourri: Quotes, resources, and collective wisdom
While working on the Testing Anti-patterns series over the past few months, I’ve had the pleasure of reading some great writing on testing, test-driven development, code coverage analysis, and the bigger picture of software quality in general. What follows is a collection of some of my favorite findings: quotes and resources spanning the last ten years and then some.
How not to test
Let’s start off with something light. James Carr’s TDD Anti-pattern Catalogue is a good, fun read that’s downright hilarious at times (but only because we remember writing seeing these tests once or twice). And not only are the anti-patterns that James proposes worth reading, you owe it to yourself to check out the extensive discussion in the comments as well. There you’ll find folks chiming in with many additional gems, including:
- The Blue Moon - Matt Simner’s aptly-named anti-pattern is one we’ve all hit at least once: “A test that’s specifically dependent on the current date, and fails as a result of things like public holidays, leap years, weekends, 5-week months, etc.” Ouch.
- Honest Guv - Graham Lenton’s contribution to the list brings back some memories I’d rather forget: “Where the expected outcome is so entropic that the developer simply asserts true with a comment ‘this works, honestly.’” Um. Sure it does.
We’re still figuring this stuff out
Some tests are just so incredibly rotten that it’s easy to definitively declare a better approach, but it’s not always that black and white. Just as we have to make trade-offs when designing and developing production code, so too do we have to weigh the advantages and disadvantages of the available approaches for testing that code.
In his post on Developer Testing and the Importance of Context, Jay Fields reflects on the catalog of testing patterns he’s documented over the past few years, and he reminds us that “context is still king:”
You’ll find that some of [the] approaches are in direct conflict. This isn’t because one pattern is superior to another in isolation, it’s because one pattern is superior to another in context.
Software development certainly isn’t the only engineering discipline that requires its practitioners to manage trade-offs, so how do we compare with other industries? The often controversial (but always entertaining) Neal Ford argues that “testing is the engineering rigor of software development,” but that we’ve still got a long way to go if software development will ever truly be an engineering discipline:
It may just be that software will always resist traditional engineering kinds of analysis. We’ll know in a few thousand years, when we’ve been building software as long as we’ve been building bridges. We’re currently at the level in software where bridge builders were when they built a bridge, ran a heavy cart across it, and it collapsed. “Well, that wasn’t a very good bridge. Let’s try again.”
Pragmatic use of code coverage analysis
We’ve talked quite a bit about code coverage in our discussion of testing anti-patterns. Brian Marick’s 1997 paper titled How to Misuse Code Coverage is a must-read, full of pragmatic advice from a veteran tester:
I’ve written four coverage tools … I still find myself looking at a coverage condition, saying “I know how to satisfy that,” and getting an almost physical urge to write a quick-and-dirty test that would make the coverage tool happy. It’s only the certain knowledge that customers don’t care if the coverage tool is happy that restrains me.
The most common coverage mistake is giving into that urge. I warn against it by saying that coverage tools don’t give commands (“make that evaluate true”), they give clues (“you made some mistakes somewhere around there”). If you treat their clues as commands, you’ll end up in the fable of the Sorcerer’s Apprentice: causing a disaster because your tools do something very precisely, very enthusiastically, and with inhuman efficiency - but that something is only what you thought you wanted.
Designing your initial test suite to achieve 100% coverage is an even worse idea. It’s a sure way to create a test suite weak at finding those all-important faults of omission. Further, the coverage tool can no longer tell you where your test suite is weak - because it’s uniformly weak in precisely the way that coverage can’t directly detect. Don’t use code coverage in test design. The return on your testing dollar (in terms of bugs found) is too low.
Now that we know how to misuse code coverage, the Google Testing Blog weighs in on the proper application of coverage analysis:
Make your tests as comprehensive as you can, without coverage in mind. This means writing as many test cases as are necessary, not just the minimum set of test cases to achieve maximum coverage.
Check coverage results from your tests. Find code that’s missed in your testing. Also look for unexpected coverage patterns, which usually indicate bugs.
Add additional test cases to address the missed cases you found in step 2.
Repeat step 2-3 until it’s no longer cost effective. If it is too difficult to test some of the corner cases, you may want to consider refactoring to improve testability.
In Code Complete, Steve McConnell offers sage advice for knowing when you can reasonably move to Step 2. (Hint: Just testing the happy path ain’t gonna get you there.):
Immature testing organizations tend to have about five clean tests for every dirty test. Mature testing organizations tend to have five dirty tests for every clean test. This ratio is not reversed by reducing the clean tests; it’s done by creating 25 times as many dirty tests.
And we should always keep the value of code coverage (or any isolated metric for that matter) in perspective, as Andy Glover reminds us in his post on unambiguously analyzing metrics:
Metrics are more copasetic when combined with other metrics and trended – for instance, complexity alone is somewhat interesting, but pairing complexity with code coverage paints a much more detailed metric that bears understanding. High complexity with low coverage is clearly more risky than the same complexity with high code coverage …
Beyond developer testing
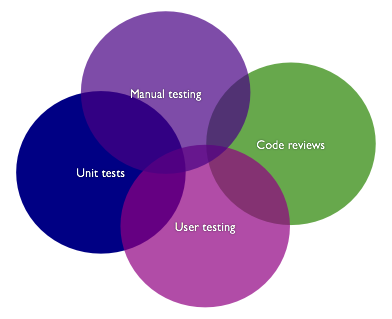
Not only should we avoid relying on a single metric, we should also be wary of relying too much on a single form (or a single “layer”) of testing. As Luke Francl argues in his call for more diverse testing, even the most exhaustive set of unit tests is limited in the scope of defects it can find [1]:
Don’t put all your eggs in one basket. The most interesting thing about these defect detection techniques is that they tend to find different errors. Unit testing finds certain errors; manual testing others; usability testing and code reviews still others.
In his post on The Ultimate Unit Test Failure, Jeff Atwood comes out swingin’ and begs development teams to invest in interaction design with the same enthusiasm (or perhaps more) that we give to developer testing:
Perfectly executed code coverage doesn’t mean users will use your program. Or that it’s even worth using in the first place.
No silver bullet
If there’s any one theme that we can observe across this collection of ideas, it’s the recognition that no recipe, or tool, or one-size-fits-all process offers the One True Way (TM) to develop quality software. As Michael Feathers points out, quality doesn’t come from a “mechanistic” approach to testing:
Quality is a function of thought and reflection - precise thought and reflection. That’s the magic. Techniques which reinforce that discipline invariably increase quality.
It’s only that critical thought that will tell us when it would be more cost-effective to use one flavor of testing over another. It’s only that critical thought that will uncover implied requirements in a user story or prompt us to ask about hidden assumptions that might be lingering in a given use case. It’s only that critical thought that will recognize when the pattern that’s worked for us 95% of the time simply isn’t appropriate for the particular scenario we’ve just come across. To forgo that critical thought in search of a silver bullet, that’s the ultimate testing anti-pattern.
Notes
[1] Luke notes that the specific overlaps in the diagram are admittedly arbitrary. The specific areas of overlap are insignificant for our purposes here. Noteworthy is that while there is some overlap between these forms of testing, each one tends to identify at least some defects that are less likely to be identified by other forms of testing. (Diagram used with permission.)
This post is part of the Testing Anti-patterns series: a series of essays taken from a conference talk titled, How To Fail With 100% Test Coverage.
–
Thanks to Stuart Halloway, Rob Sanheim, and Greg Vaughn for reading drafts of this post.